
Let's Play Jeopardy! with LLMs
How good are LLMs at trivia? I used the Jeopardy! dataset from Kaggle to benchmark ChatGPT and the new Llama 3 models. Here are the results:
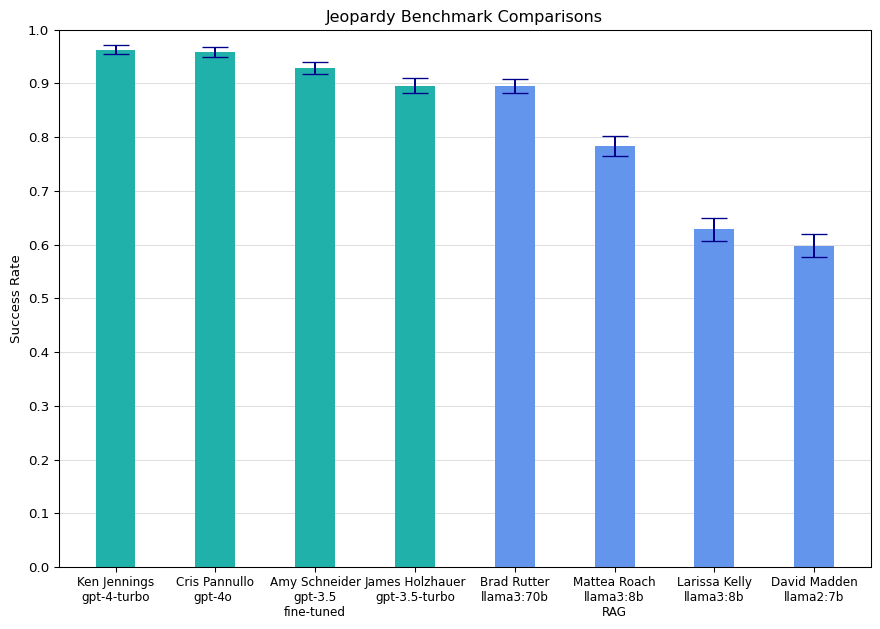
There you go. You’ve already gotten 90% of what you’re going to get out of this article. Some guy on the internet ran a half-baked benchmark on a handful of LLM models, and the results were largely in line with popular benchmarks and received wisdom on fine-tuning and RAG.
Still, the process was interesting, so I’m going to talk about it. At length. You’ve been warned.
All code for this article is available on GitHub.
Project Goals
- Have my own point-of-view on Llama 3 vs. ChatGPT.
- Demonstrate fine-tuning has a measurable benefit.
- Demonstrate RAG has a measurable benefit.
- Have fun and pay homage to Jeopardy!, the greatest trivia show of all time.
There’s one undeniable advantage to rolling your own benchmark, no matter how half-baked: you can be sure that implementers are gaming the metrics by “teaching to the test” and including benchmark data in the pre-training or fine tuning of their model. It’s widely suspected that many popular benchmarks are at least a little poisoned in this way.
For fine-tuning, OpenAI provides by far the easiest path. Since they only offer fine-tuning on 3.5, we’ll benchmark gpt-4-turbo, gpt-3.5, and a fine-tuned version of gpt-3.5. That will let us see where fine-tuning lands between 3.5 and 4 and gives us a spread to compare against Llama 3.
For Llama 3, we’ll want to test both the big and small versions of the model. I’m mainly interested to see how Llama 3 stacks up against ChatGPT, but I’ve also included one Llama 2 model to see if Llama 3 is an improvement.
For RAG, we’ll build a small local database and then use it to augment one of the smaller Llama 3 models. Not only will that keep inference costs low but the benefit of RAG should be easier to see if we start from a lower baseline. We’ll have to be careful with CV (described below.)
Let’s start by taking a look at the dataset.
The Dataset
A couple of years ago, I found this fantastic dataset of Jeopardy! questions on Kaggle. I never really did anything with it, but recently I dusted it off and took another look. This time, I could see a pretty clear use for it. In 2011, IBM Watson playing Jeopardy! was a major achievement. In 2024, it’s a weekend project.
The dataset consists of 200,000+ question/answer pairs, plus the category (column) and value (row) of the question. Here is a sample to give you an idea of what it contains:
| category | air_date | question | value | answer | round | show_number |
|---|---|---|---|---|---|---|
| THE GOOD BOOK | 2006-05-22 | ‘Jeremiah asks, “Is there no balm in” this land?’ | 400 | Gilead | Jeopardy! | 5006 |
| OLD MEDICINE TERMS | 1999-07-19 | ‘This name for tuberculosis referred to the wasting away of the patient’ | 200 | Consumption | Jeopardy! | 3441 |
| NUMBER OF LEGS ON… | 2004-03-04 | ‘A muskellunge’ | 1600 | 0 | Double Jeopardy! | 4494 |
| PALINDROMIC WORDS | 2007-12-06 | ‘It’s “the word” when keeping silent’ | 400 | mum | Jeopardy! | 5349 |
| “WA”? | 2010-05-11 | ‘This principality united with Moldavia to form Romania’ | 1600 | Wallachia | Double Jeopardy! | 5917 |
Just to be clear, this dataset follows the convention that the “question” is the prompt that Alex reads, and the “answer” is what the contestant should respond with… in the form a question, of course. That is the convention I’ll stick to for this project.
It has a number of features that make it ideal grist for the LLM mill:
- Mainly free text, necessitating some kind of NLP or LLM approach.
- Comes in handy prompt/response pairs.
- Exercises knowledge, wordplay, and some inference.
- Questions are quite short, so no chunking is necessary.
- Good mix of easy and hard questions.
- Medium difficulty overall, making it suitable for benchmarking.
If you plan on using the Jeopardy! dataset yourself there are two “gotchas” that you should be aware of:
First, the “value” column is a currency field with a leading $ and
thousand separators, although this is currently inconsistent. The functions
clean_currency() and load_jeopardy_dataset() show how to
handle this minor data quality issue.
Second, some questions use audio or visual cues that are represented in the
dataset as links to external resources. These questions are unfair to the LLMs
because the clue as given doesn’t contain enough information to narrow it down
to a unique answer. load_jeopardy_dataset() has an optional flag for
removing questions containing an external link. Don’t worry; even after
removing all the “unfair” questions, over 200,000 “fair” questions remain.
Prompt Engineering
We’ll centralize a few other things that will be the same across all contestants, namely the prompt template and system messages:
jeopardy_question_template = '''
CATEGORY: {category}
{clue}
'''
system_messages = [
{
"role": "system",
"content": ("You are a contestant on Jeopardy. Each prompt has both the "
"category (column header) and Jeopardy clue; answer in the form "
"of a question."),
},
{
"role": "user",
"content": ("CATEGORY: THE BIG APPLE\nThere's an annual footrace up its "
"86 flights of stairs"),
},
{
"role": "assistant",
"content": "What is the Empire State Building?"
}
]
I say system_messages, but it also includes one example of a correct
question/answer pair. Every conversation will start with the exact same prompts
so that we have a level playing field for all contestants.
Inference
Retry Logic
No API is 100% reliable. OpenAI has been pretty unreliable over the past year but, in all fairness, it was pretty solid for this project. The AWS Bedrock API is less mature and experienced many random failures during this project.
# reusable decorator to implement basic retry logic. We make up to three
# attempts with exponential backoff.
retry_decorator = tenacity.retry(
wait=tenacity.wait_exponential(min=0.1, max=2),
stop=tenacity.stop_after_attempt(3),
after=tenacity.after_log(logger, logging.ERROR),
reraise=True)
We use three retries because as the old saying goes, “four is too many and two isn’t enough.” I don’t why this is the case, but every programmer knows it to be true deep in within their soul. It seems to be part of the shared subconscious, similar to how 37 is the most random number.
Player Agents
To keep things simple, we’ll model our agents as simple Python functions. The function signature for contestants should look like this:
PlayerAgent = Callable[[str, str], str]
Here’s a dummy implementation of a PlayerAgent:
# example:
def contestant(category: str, clue: str) -> str:
answer = 42
return f"What is {answer}?"
To keep things light, we’ll name all our agents after famous Jeopardy! stars. We’ll start with Ken Jennings, perhaps the greatest Jeopardy! player of all time.

Ken will use GPT-4 Turbo, which is similarly best-of-breed when it comes to LLM agents.
To smooth over the occasional API hiccup, we’ll use the retry_decorator from
above, which doesn’t change the function signature. Then its simply a matter of
formatting the parameters into a prompt (using the above template,) sticking on
the shared system messages (so it understands the task,) and hitting the API.
@retry_decorator
def ken(category: str, clue: str) -> str:
'''PlayerAgent for GPT-4. Calls OpenAI.'''
prompt = jeopardy_question_template.format(**locals())
chat_response = client.chat.completions.create(
model="gpt-4-turbo",
messages=system_messages + [
{"role": "user", "content": prompt}
]
)
content = chat_response.choices[0].message.content
return content
Most contestants will look very similar to this, just with minor variations
like using a different model name, swapping client.chat for ollama.chat,
doing a little formatting for Llama 3, etc.
In Jeopardy!, the category (column header on the board) is often crucial. It can provide an initial letter, a word length, a time period, or other essential context without which the answer might be ambiguous. For that reason, we use it as part of the prompt template.
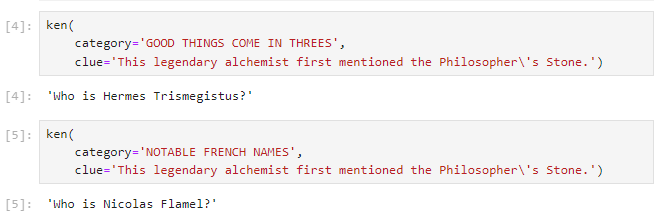
In the first prompt, the category “THREES” is a clue pointing to the
“Thrice-Great” alchemist, while “FRENCH” is the crucial clue that tells us
Flamel is probably who is meant. Ken (who you’ll recall from above is a wrapper
around gpt-4-turbo) is smart enough to use that context.
Arguably the dollar value should be included as well, since in theory knowing if the question is supposed to be easy or obscure could help with guessing, but this is tenuous and I haven’t done so here.
Hardware
Models have to run somewhere - even the cloud is just someone else’s hardware. For OpenAI, our choices are Azure or OpenAI’s own servers, since the model weights are proprietary and cannot be run locally. We’ll use OpenAI’s server for this project.
Llama is more open. You can download and run the models locally if you have a
powerful enough computer. There are several ways to do this, but
ollama bills itself as a quick and easy way to run model locally, and
I found this to be pretty accurate. You install it, pull the model weights you
want using the CLI, and then use the Python ollama package to talk to your
local ollama server. It’s all pretty painless and worked well for llama2:7b
and llama3:8b.
Sadly, my graphics card “only” has 12 GB of VRAM, so I wasn’t able to run the
llama3:70b locally. (Works great for games though! You should see it run
Cyberpunk 2077.)
Instead, I used AWS Bedrock for inference, as they just recently added
the Llama 3 models. This introduces a slight wrinkle - the boto3 Bedrock API
is model agnostic and accepts a single “prompt” string rather than a list of
messages. You have to format the chat history yourself, and this format is
different for different models (and even different between Llama 2 and 3!)
Luckily, the format is simple and well-documented and we can implement it like so:
def format_llama3_prompt(messages: List[dict]) -> str:
'''AWS Bedrock accepts only a single string in raw format; we need to format
messages using their special tags. Llama 3 uses a different format from llama2.
'''
prompt = '<|begin_of_text|>'
for message in messages:
role = message['role']
content = message['content']
assert role in ['system', 'user', 'assistant']
prompt += f'<|start_header_id|>{role}<|end_header_id|>{content}<|eot_id|>'
prompt += '<|start_header_id|>assistant<|end_header_id|>'
return prompt
All in all, we’ll be using three different libraries for LLM inference for this benchmark, plus a fourth for the local vector database:
| Service | Provider | Library |
|---|---|---|
| gpt-4-turbo | OpenAI | openai |
| gpt-3.5-turbo | OpenAI | openai |
| text-embedding-ada-002 | OpenAI | openai |
| llama3:70b | AWS Bedrock | boto3 |
| llama3:8b | Local | ollama |
| llama2:7b | Local | ollama |
| vector database | Local | faiss |
That definitely makes getting the environment set up a bit tricky, but this is necessary complexity for a benchmark that compares across model providers and libraries.
Libraries like liteLLM offer a compatibility layer that provide a single API to call; that’s definitely something to consider if you need to use several different LLMs in one project.
Judging Correctness
For the benchmark to work, we need to know if the contestant is correct or not. Since the correct answer is given in the dataset, the fastest and easiest way to do that is with a simple string compare. The problem is that there are several correct ways to phrase an answer. In fact, sometimes the correct answer listed in the dataset actually lists more than one correct response.
On the opposite end of the spectrum, we could have a human manually check each answer. But lets think about what that would involve for a second. We need a sample size of about 2,000 to get sufficient statistical power to distinguish between similar contestants, and we have 7 different contestants to benchmark. That’s 14,000 answers to judge; and frankly there are more pleasant ways to spend a Sunday afternoon.
Instead, we use a pattern called “LLM-as-Judge”, where we ask another LLM agent to grade the response. This is a good fit for the Jeopardy! dataset because the task of deciding if an answer is correct when you can see the correct answer is much easier than actually answering it. Plus, there are many cases where the exact wording won’t match and an LLM can handle such cases while saving us the trouble of manually marking 14,000 rows of results.
Host Agent
Just as with players, we’ll also model our judge agent as a simple Python function:
HostAgent = Callable[[str, str, str, str], str]
Here’s a stub implementation of HostAgent:
def host(
category: str,
clue: str,
correct_response: str,
contestant_response: str
) -> str:
factually_correct = (correct_response in contestant_response)
phrased_correctly = (contestant_response[-1] == '?')
correct = (factually_correct and phrased_correctly)
return 'Correct! if correct else 'Incorrect.'
We need to implement the same interface delegating the judgment to an LLM. We will of course name our agent after Alex Trebek.

@retry_decorator
def alex(
category: str,
clue: str,
correct_response: str,
contestant_response: str
) -> str:
'''HostAgent used to judge respondants. This is necessary because
a correct response may not necessarily match the given answer 100%
of the time. This uses GPT-4 (calling OpenAI's API) because it makes
very few judging errors; only about 1%. Alex will always start his
response with "Correct!" if the contestant got it right, but may include
additional commentary.
'''
prompt = f'''
CATEGORY: {category}
ORIGINAL CLUE: {clue}
CORRECT RESPONSE: {correct_response}
CONTESTANT RESPONSE: {contestant_response}
'''
chat_response = client.chat.completions.create(
model="gpt-4-turbo",
temperature=0.0,
messages=[
{"role": "system", "content": ws("""
You are Alex Trebek, the host of Jeopardy. Given a correct
answer from the producer and a response (in the form of a
question) from a contestant, use your best judgement to decide
if the contestant is correct. If the contestant answered the
question correctly and in the form of a question, the first
word of your response MUST be "Correct!".
""")},
{"role": "user", "content": prompt}
]
)
content = chat_response.choices[0].message.content
return content
Bayes Rate
Asking an LLM to emulate a famous person is often effective at eliciting
high-quality responses. This seems to be the case here; with this agent
achieving high accuracy. In fact, the alex() agent often adds a little
explanation or extra trivia tidbit, just like the real Alex Trebek:
Category: THE VEEP RIGHT BEFORE...
Question: 'George H.W. Bush'
Correct Answer: Walter Mondale
Contestant's Answer: Who is Ronald Reagan?
Alex's Judgement: Incorrect. The correct response was, "Who is Walter
Mondale?" Ronald Reagan was the President before George
H.W. Bush, not the Vice President.
Category: SECOND-LARGEST CITIES
Question: 'Mosul, 1.8 million'
Correct Answer: Iraq
Contestant's Answer: What is Baghdad?
Alex's Judgement: Incorrect. The correct response is "What is Iraq?" Mosul
is the second-largest city in Iraq, not Baghdad.
I didn’t explicitly ask it to do that, so I’m not sure if it’s role playing or if this is just a reflection of the fact that ChatGPT often “over-explains” its answers even when you don’t want it to.
Here’s an example of a row in the dataset that’s problematic:
Category: "WIN"
Question: 'Seen here, Marie Barrow is holding this possession of her late
brother Clyde'
Correct Answer: Winchester rifle
Contestant's Answer: What is a gun?
Alex's Judgement: Incorrect. The correct response is "What is a Winchester
rifle?"
Here, the wording implies that a picture was shown, but without a link, the question slips past our “unfair” filter. Some quick Googling turned up what I presume to be the photo mentioned:

But of course the LLM didn’t get to see that. The given answer is actually pretty intelligent, considering that you’d have to deduce that Clyde is Clyde Barrow of Bonnie and Clyde fame, and then deduce the associated object is most likely a gun. However, it was marked wrong anyway.
Even worse, there’s another row where a different contestant was asked the same question and gave the same response, but this time it was judged correct!
Category: "WIN"
Question: 'Seen here, Marie Barrow is holding this possession of her late
brother Clyde'
Correct Answer: Winchester rifle
Contestant's Answer: What is a gun?
Alex's Judgement: Correct! The response "What is a gun?" broadly covers
the specific answer of "Winchester rifle," which is
indeed a type of gun.
So there is also some inconsistency in judging answers. I did set the temperature to zero, but I’ve heard that isn’t always enough to get 100% deterministic behavior out of GPT-4.
The above examples probably give the impression the whole LLM-as-Judge thing is flawed, but I had to read through a lot of judgements to cherry pick those errors. I didn’t formally measure it but I estimate the error to be around 1%, capping the maximum possible score to be around 99%. This means that the Bayes error rate for the Jeopardy! dataset is just under 100%. That doesn’t make it any less useful for benchmarking - many popular benchmarks have a ton of errors. As long as the errors are not too common it doesn’t make much practical difference since all LLMs will be penalized in the same way.
Agentic Workflow
Now that we have a couple of agents, we can wire them together into what are called “agentic workflows.” Since we modeled our agents as Python functions, this is straightforward:
def jeopardy_dialogue(
question_data: dict,
contestant: PlayerAgent,
host: HostAgent = alex) -> Tuple[str, str]:
'''Handles one question/answer/judgement interaction between the host
and a contestant. The question is converted to a category and clue
and passed to the contestant, who answers. Then the original question,
the correct answer, and the contestant's given answer are passed to
the host for judgement.
'''
q = question_data
question = q['question'].strip("'")
contestant_answer = contestant(q['category'], question)
judgement = alex(q['category'], question, q['answer'], contestant_answer)
return contestant_answer, judgement
For the benchmark, we need only a linear question/answer/judgement flow, but it’s probably not hard to imagine expanding this to a workflow that implements a proper game of Jeopardy!, with three contestants, score tracking, and so on. It’s easy to imagine because you already know how to create loops, control flow, and error handling in Python.
There are of course libraries available that will help you make this way more complicated and opaque, but somehow simultaneously more rigid, if that’s your kind of thing. This is apparently a good way for beginners to get started because as we all know, there’s nothing more educational than calling a high-level interface that hides many of the underlying implementation details and replaces them with its own ersatz concepts.
Ahem. Getting back on track, we can then our benchmarking framework on top of that. First, ask a contestant a random sample of questions and record the results:
def jeopardy_benchmark(contestant, dataset, sample_size=3) -> pd.DataFrame:
'''collects benchmark data for one contestant by choosing `n` random questions
from the dataset, putting the question to the contestant agent, and using the
`alex()` agent to determine correctness.
'''
jeopardy_sample = random.sample(dataset, sample_size)
for question_data in jeopardy_sample:
contestant_answer, judgement = jeopardy_dialogue(
question_data=question_data,
contestant=contestant)
question_data['contestant_answer'] = contestant_answer
question_data['judgement'] = judgement
# parse the host's free-text response to get a Boolean flag.
question_data['correct'] = judgement.lower().startswith('correct')
jeopardy_df = pd.DataFrame.from_records(jeopardy_sample)
return jeopardy_df
Then do that for a list of contestants:
def jeopardy_benchmark_suite(
jeopardy_data: List,
contestants: List = None,
sample_size: int = 3,
seed: int = None) -> pd.DataFrame:
'''Runs the Jeopardy! benchmark for a number of contestants. All
contestants receive the exact same set of questions. Results
are returned in a single dataframe with contestants distinguished
by the "label" column.
'''
all_benchmark_results = []
if contestants is None:
contestants = [amy, ken, larissa, david, brad, james, mattea]
if seed is None:
seed = sample_size
with TemporarySeed(seed):
for contestant in contestants:
benchmark_results_df = jeopardy_benchmark(
contestant,
dataset=jeopardy_data,
sample_size=sample_size)
benchmark_results_df.insert(0, 'label', contestant.__name__)
all_benchmark_results.append(benchmark_results_df)
all_benchmark_results_df = pd.concat(all_benchmark_results)
return all_benchmark_results_df
Finally, collate the raw results down to a summary for each contestant:
def evaluate_jeopardy_benchmark(benchmark_results: pd.DataFrame, label=None) -> dict:
'''Evaluates the performance of a single contestant, i.e. computes
success rate and standard error.
'''
successes = benchmark_results['correct'].sum()
failures = (~benchmark_results['correct']).sum()
sample_size = successes + failures
# Compute proportion and standard error
success_rate = successes / sample_size
safe_success_rate = (successes + 0.5) / (sample_size + 1)
se = math.sqrt(safe_success_rate * (1 - safe_success_rate) / sample_size)
# human readable error bars
margin_of_error = 1.96 * se
return {
"label": label,
"successes": successes,
"failures": failures,
"sample_size": sample_size,
"success_rate": success_rate,
"standard_error": se,
}
This gives us the underlying data that was plotted on the bar chart at the top.
Fine-Tuning
One of the things I wanted to benchmark was the effect of fine-tuning. Does it really measurably improve performance?
OpenAI expects fine-tuning training data to be provided in the JSONL
format with one example per line. Each line should be a JSON object containing
the messages for one chat session, using the same message format used by the
chat.completions API.
It’s easy to implement the specified format:
def format_for_fine_tuning(
category: str,
question: str,
answer: str,
**kwargs) -> dict:
'''formats one question/answer pair as one line in an OpenAI
fine-tuning .jsonl file.
'''
messages = [
{
"role": "system",
"content": ("You are a contestant on Jeopardy. Answer in the "
"form of a question.")
},
{
"role": "user",
"content": f'\nCATEGORY: {category}\n{question}'
},
{
"role": "assistant",
"content": f"What is {answer}?"
}
]
return { "messages": messages }
We include the same system prompt that we will use for the task, and we provide the Jeopardy! question in the exact same format we will use for the real task. We omit the “1-shot” example - the fine-tuning should now fill the same role. Finally, note that we take the opportunity to teach it that every response should be in the form of a question. (Many contestants such as Matt Amodio invariably use the form “What is X?” instead wasting time thinking about the appropriate interrogative.)
The function jpt.generate_fine_tuning_data() runs this for a random
sample of data and writes it to a file. I’ve also included a sample of the
resulting JSONL file.
Fine tuning on 1,000 examples took about 30 minutes and cost about a dollar. However, inference is also more expensive for a fine-tuned model than for baseline GPT-3.5 - only slightly less expensive than GPT-4 Turbo. That means that in a typical production setting most of the expense won’t be the initial fine-tuning but rather usage over time.
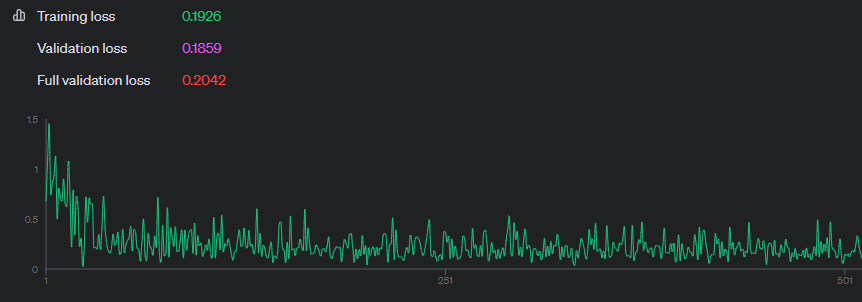
Interestingly enough, most of the benefit of fine-tuning is achieved in the first ten minutes. This is consistent with the fact that fine-tuning on 10k didn’t improve performance over training on 1k. I’ll discuss this in more detail in the conclusion below.
Calling the fine-tuned model is simply a matter of passing a new model ID to
the API. We’ll this wrap this in another standard PlayerAgent function. This
one is named after Amy Schneider, who had a 40 game winning streak and would
often go several games in a row without a single mistake.

@retry_decorator
def amy(category: str, clue: str) -> str:
'''PlayerAgent for a fine-tuned GPT-3.5-Turbo. Calls OpenAI.'''
prompt = jeopardy_question_template.format(**locals())
chat_response = client.chat.completions.create(
model="ft:gpt-3.5-turbo-1106:personal:jeopardy1k:9MJuormU",
messages=system_messages + [
{"role": "user", "content": prompt}
]
)
content = chat_response.choices[0].message.content
return content
Obviously I don’t recommend hard-coding the fine-tuned model ID like this, but since this project is only intended to run once there’s no need to future-proof.
As an aside, I wish OpenAI had a way to register named “versions” of a model, like MLFlow and similar tools. Having to change the config for your client code every time you re-run the fine-tuning is kinda annoying, but not a deal-breaker.
Vector Database
For RAG, we’ll want to use a vector database to store and quickly retrieve
semantically related questions. One nice thing about the Jeopardy! dataset is
that every question is much, much shorter than the 8,191 token limit on
the text-embedding-ada-002 model. (What happened to that 8,192nd
token, I wonder?) That means we don’t have to think about “chunking” at all -
we’ll just make a separate chunk for each question.
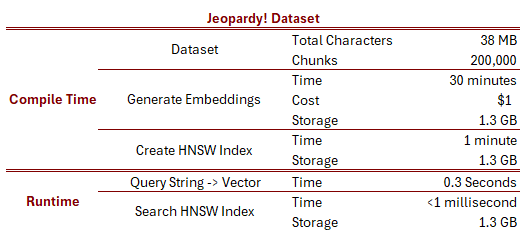
This has the effect of greatly inflating the size of the dataset. A 1,536 dimensional vector of 32-bit floats takes up 6,144 bytes each. So 200,000 vectors require a total of 1.2 GB. Storing the original question data and the exact chunk text brings that up to 1.3 GB. That means 90% of our database size is just the embedding vectors. That isn’t normally the case; when making use of the full 8,191 tokens for each chunk, the original text and vectors take up roughly the same amount of space. Nevertheless, I think it’s the right call use use one chunk per question, because it wouldn’t make any sense at all to confuse things by stuffing multiple questions into each chunk. Sure, it would take up less space, but the semantic vectors from multiple questions would be muddled together, and when you’d retrieve a chunk you’d pull in dozen unrelated questions.
It takes about 30 minutes to generate embeddings for all 200,000 questions, and then another minute to generate a local HNSW index for them. Luckily, we only have to do that once.
The 1.3 GB index takes one second to read off disk, but again, that’s something we only need to do at the start of each process. Once it’s loaded, querying the vector database is incredibly fast - less than one millisecond. In fact, it’s dwarfed by the time it takes to hit OpenAI’s embedding API to convert query strings into vectors. (I wonder if we could achieve lower latency with a local embedding model? But most of the really good embedding models seem to be proprietary… how much recall and precision are we prepared to give up for faster results?)
Here’s a summary of these different costs and times:
Brute Force
It’s interesting to compare HNSW to the brute force approach. Here is how you would implement exact search using cosine similarity:
distances = 1.0 - (database @ query)
Where @ is the Python operator for matrix multiply. Alright, fine,
there’s a little more ceremony to it:
def best_k(database: np.ndarray, query: np.ndarray, k: int = 5):
'''Brute force best-k algorithm. Simply computes *all*
the cosine distances between the query and every embedding
vector in the database and returns the top-k in sorted order
(lowest distance first.) Call `brute_force_search()` for
a higher level interface.
'''
# Normalize the query vector
query = query / np.linalg.norm(query)
# Compute cosine distances
distances = 1.0 - (database @ query)
# Find the indices of the k smallest distances
best_k_unsorted = np.argpartition(distances, k)[:k]
# Sort these indices by distance
sorted_indices = np.argsort(distances[best_k_unsorted])
best_k_sorted = best_k_unsorted[sorted_indices]
best_k_distances = distances[best_k_sorted]
return best_k_distances, best_k_sorted
But that one matrix multiply is doing all the work; the rest is negligible in comparison.
The brute force strategy is surprisingly viable for small vector stores up through about 10,000 vectors, but by the time we’ve past 100,000 vectors it’s definitely time to switch to something more sophisticated. For this database of 200,000 vectors the HNSW algorithm (which scales as $O(\log n)$ for search) is more than 100 times faster than brute force.
Not that it really matters for this use case, because whichever we use the 0.3 second latency for calling the OpenAI embeddings API to convert the query string into a query vector is still going to be the bottleneck.
Cross-Validation
One thing to consider when benchmarking RAG is that it’s not very interesting to simply prove we can memorize and retrieve 200,000 records - any idiot with a database could do that. We want our agent to generalize to novel questions it hasn’t seen before. That’s definitely possible, because a lot of trivia questions are actually pretty similar. Jeopardy! doesn’t repeat questions verbatim, but there’s plenty to be learned by simply watching the show.
We could split the dataset randomly - with one split feeding the vector
database and the other being used for benchmark questions - but instead we used
the air_date field to do a time series split. All questions from
before the split date are available to the agent via RAG, and all questions
asked on the benchmark are sampled from after the split date.
I picked a date from about a year before the end of the dataset to simulate the experience of a typical contestant on the show - they would have had access to questions from prior seasons, but not newer ones.
RAG Agent
The contestant that we use to benchmark RAG looks like this:
@retry_decorator
def mattea(category: str, clue: str) -> str:
'''PlayerAgent implementing the RAG pattern. It only knows the
exact answers to questions from before 2011-01-01. It uses llama3:8b,
a fast but fairly dumb model, so we can see the bump from RAG clearly.
'''
# find similar past questions
rag_query = f'CATEGORY: {category}\n{clue}'
embeddings_old, jeopardy_old = old_jeopardy()
augment_data = brute_force_search(
embeddings_old, jeopardy_old, query=rag_query, k=10)
augment_json = json.dumps(augment_data)
# augment the prompt with retrieved questions
prompt = jeopardy_question_template.format(**locals())
# this looks cheesy, but other attempts to embed the RAG context
# resulted in Llama 3 being confused about which question's were historical
# and which was actually being asked. This prompt fixed that.
messages = system_messages + [
{"role": "user", "content": ("Correct! By the way, here are three historical "
"questions that may help you answer future "
"questions: {augment_json}")},
{"role": "assistant", "content": ("Thank you, I'll be sure to refer back to "
"those if they help with a question in the "
"future!")},
{"role": "user", "content": prompt}
]
# use a small, fast model for generation
response = ollama.chat(
model='llama3:8b',
messages=messages
)
content = response['message']['content']
return content
It’s named after Mattea Roach, the most successful Canadian contestant of all time.

We also need special handling when it comes time to benchmark mattea().
Unlike the other agents, we can’t simply sample from all the fair questions;
because of split, we must be careful to only sample questions after the split
date:
jeopardy_data = load_jeopardy_dataset(remove_unfair=True)
split_date = '2011-01-01'
jeopardy_new = [ q for q in jeopardy_data if q['air_date'] >= split_date ]
mattea_benchmark_results_df = jeopardy_benchmark(
contestant=mattea,
dataset=jeopardy_new,
sample_size=2000)
We can then combine Mattea’s results with the others to obtain the final dataset used for the bar chart at the top of this article.
all_benchmark_results_df = pd.concat([
old_benchmark_results_df,
mattea_benchmark_results_df
])
The logic for this is found in the Mattea CV Benchmark notebook.
Conclusions
Now that we understand what the different parts mean, let’s take another look at the summary bar chart:
And here are the same results as a table:
| Contestant | Model | Variation | Successes | Failures | Sample Size | Success Rate | 95% CI |
|---|---|---|---|---|---|---|---|
| Ken Jennings | gpt-4-turbo | 1,924 | 76 | 2,000 | 96.20% | ±0.84% | |
| Cris Pannullo | gpt-4o | 1,917 | 83 | 2,000 | 95.85% | ±0.88% | |
| Amy Schneider | gpt-3.5 | fine-tuned | 1,856 | 144 | 2,000 | 92.80% | ±1.13% |
| James Holzhauer | gpt-3.5-turbo | 1,791 | 209 | 2,000 | 89.55% | ±1.34% | |
| Brad Rutter | llama3:70b | 1,790 | 210 | 2,000 | 89.50% | ±1.34% | |
| Mattea Roach | llama3:8b | RAG | 1,567 | 433 | 2,000 | 78.35% | ±1.81% |
| Larissa Kelly | llama3:8b | 1,257 | 743 | 2,000 | 62.85% | ±2.12% | |
| David Madden | llama2:7b | 1,196 | 804 | 2,000 | 59.80% | ±2.15% |
The sample size of 2,000 gives us pretty good statistical power. The 95% confidence interval for each measurement is only a few percentage points wide.
Except for James (gpt-3.5-turbo) and Brad (llama3:70b), who are basically tied, the difference between successive rows are all statistically significant. That means its appropriate to treat these differences being meaningful.
Let me wrap this up by giving my thoughts on what this benchmark taught us about the various different things we tried.
GPT-4o “Omni”
OpenAI released their new GPT-4o “Omni” model literally the day after I first published this article, so I went back and quickly added it to the suite. It’s performance is right between GPT 4 and 3.5 which is in line with others have reported.
GPT-4o has many other capabilities that were the focus the release:
- Needle-in-a-Haystack performance is drastically improved, making it more effective at using the full 128k context window.
- Multi-modal model results in more natural speech.
- Faster speed and lower latency results in more natural, real-time conversation.
- Half the price of GPT-4 Turbo.
But I’m just regurgitating the sales brochure at this point - this benchmark shows that whatever it’s other assets, GPT-4 Turbo still has the highest quality responses.
Fine-Tuning
Fine-tuning works, but it’s a “you get what you pay for” kind of deal. OpenAI’s rates for fine-tuned models are midway between GPT-4 and GPT-3.5, but so is performance. Then there’s the headache of curating and maintaining a fine-tuning dataset… unless you actually beat a GPT-4 model with your fine-tuned GPT-3.5 model (which is going to be very use case dependent) it’s a lot of complexity for a very marginal cost savings. “Almost as good, and slightly cheaper” just doesn’t have the same ring as “Almost as good, and a lot cheaper.”
Of course, when OpenAI finally starts offering fine-tuning of GPT-4 models, fine-tuning may allow us to unlock a whole new level of performance, but that’s future state. Right now it’s very situational.
One thing that surprised me about the fine-tuning is that the performance gains all came from the first few hundred records. The training loss curve flattened out pretty quickly and there wasn’t any benefit from fine-tuning on a larger 10k dataset. That means we’re not teaching the model the answers to specific trivia questions, we’re teaching it how to be a Jeopardy! contestant. That’s also why the performance bump generalizes to novel data - it’s not about memorization. That tells us that fine-tuning is the tool we should reach for to steer our models: to improve compliance or to stay on task.
RAG
RAG gives us a whopping 15-percentage-point advantage over the baseline model. It doesn’t quite get us all the way up to the performance of the 70-billion-parameter version, but that’s still a very impressive gain especially considering how fast and cost effective it is.
The added 0.3 second latency for hitting the embeddings API is probably the biggest downside. That latency probably isn’t coming from the actual embedding model; it the typical latency you’d see with any HTTP request that has to make a round trip across the internet.
It’s enough to make me wonder if running a local embedding model would be worth it for the reduction in latency alone… Many popular embedding models, such as OpenAI’s or Voyage AI’s, are proprietary and require just such a round trip over HTTP, but there are also open models that do well on benchmarks such as MTEB.
The vector database itself is pretty inexpensive to index and essentially free to query if you use HNSW so unless you’re operating at Wikipedia scale the costs will be nominal; it’s really the embeddings call that gets you.
Of course, you don’t have to use RAG with a small model like we did; you could pair it with GPT-4 or other SOTA if you’re focused on quality over throughput, latency, or cost. Unlike fine-tuning, RAG doesn’t lock you into a particular LLM choice.
I see why there’s a lot of hype around RAG and HNSW; it’s cheap, it’s fast, it scales well, it’s easy to implement (you don’t have to hand-curate training examples but just chunk whatever useful documents are lying around), it’s flexible (you can mix-and-match with any LLM to acheive the right balance of cost, quality, and speed) and above it works, giving noticeable improvement in task performance and answer quality.
Llama 3
Llama 3 is definitely behind ChatGPT across the board on this benchmark - the largest and best performing Llama 3 model is tied with OpenAI’s “for occasional use around the home” GPT-3.5 model.
Parameter size is likely to have an outsized impact on this particular benchmark because this kind of knowledge based task heavily handicaps smaller models - all that world knowledge has to live somewhere - and a lot of the improvements reportedly made by Llama 3 over Llama 2 are about reasoning and usability, not breadth of knowledge.
We don’t know how large GPT-3.5 is exactly; speculation puts it at around 40 billion parameters, but no one knows for sure. For all I know it’s also 70 billion and the only difference between OpenAI and Meta is that OpenAI has spent more on GPUs. Or it could be that OpenAI has a few secrets that give them an algorithmic edge.
Regardless of how it’s achieved, OpenAI still has the lead, and Meta did not manage to fully close the gap with Llama 3. At least not on the only benchmark that really matters, the only benchmark that truly represents an AI-complete measure of general intelligence: the ability to win money on a TV game show.